


All animals are equal, but some animals are more equal than others.
- George Orwell (The Animal Farm)
In the 2020s, you don't need to be an Oracle to know that all data is not equal. It is staring us right in our face with the explosion of data being generated daily. Across domains, we have started looking at mechanisms to classify and maintain data based on its relevance or importance. An obvious end to this is in being able to get what is needed as soon as the need arises.
Understanding Data
Let's start by first setting the context. This discussion refers to machine data and its use specifically in the area of security and operational monitoring. Within the whole data explosion phenomenon, the increase in machine-generated data is perhaps the most significant. A massive challenge that we are facing today is to make machine-generated data actionable in a cost-effective manner.
When we ask CISOs today whether they consume all the event data across IT systems and applications in their security monitoring solutions, the overwhelming response is that they simply cannot think of doing this because of the scale of the infrastructure required to do so. (Check out this blog to learn how to prioritize your actions in your first 90 days as a CISO.)
Event data generated by machines can be broadly categorized as :
- Telemetry: Events to measure key operational parameters - CPU utilization, IOPS etc.
- Errors and Alerts: Events pertaining to errors faced during operations
- Notifications: General notifications of what just happened on the device
- User Activity: Notifications which identify what was done by users of the machine
- Administration Activity: Changes are done in settings or administration parameters of the device
Most devices have adopted standardized log formats and event identifiers with improving logging standards. This has greatly helped device manufacturers improve troubleshooting and performance monitoring of the devices. Today most devices provide specific Event IDs and generate logs in consumable formats by log analytics applications.
A simple assessment of the above categories would reveal that neither all data above is generated at the same volume nor has the same level of importance and relevance over a period of time.
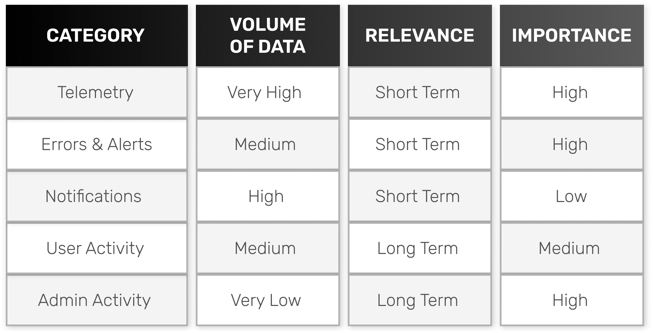
It is still observed that although most log monitoring applications are able to understand the log formats and Event IDs, none of them treats the different types of data differently. All event data in log monitoring applications continue to be treated with the same level of importance and are retained for the same amount of time.
This is clearly a mistake this industry overlooked for a long period of time.
Data analysts take huge pains in creating parsers to identify, parse, annotate and enrich log events from different applications. An obvious extension of this would also be to bucket these events in such a way that makes it possible to store and retain data as per the category. This would give users the flexibility to search and retain data based on the type and hence maximize utilization of the same. A more appropriate mode of storing this data would be as follows:

Taking this approach at an enterprise-level allows users to store exactly the data that is needed to be stored and at the level of resiliency and performance which is needed.
What is DNIF HYPERCLOUD doing about this?
Our engineers at DNIF HYPERCLOUD have made architectural optimizations and have included the above concept at the core of our product design. This data driven approach is helping our customers to reduce blind spots and get the best ROI.
- DNIF HYPERCLOUD stores data in ‘Streams’. Streams are categories of data according to the type of event.
- Each Stream can be configured to have an independent retention period.
- Users can define the number of replicas for the data at a Stream level allowing them to control the query performance and resiliency.
- Queries are executed at a stream level giving the fastest possible response times.
DNIF HYPERCLOUD is cloud-native and delivers unlimited scalability with functionality that brings back threat detection to the forefront.
Schedule a demo with us to learn more about how DNIF HYPERCLOUD can help your organization.
